
Vibe Research: Training, Safeguarding, and Evaluating Research Agents in a Lab
Published:
Abstract. This post is a written version of my “Vibe Research” slides: https://vibe.oushigang.com/. The core claim is simple: the next leverage point in AI-for-science is not only stronger models, but lab environments that allow expert taste, context, and judgment to flow into research agents. A useful research agent system needs three things: training through shared context and skills, safeguarding through infrastructure and long-running harnesses, and evaluation through expert intervention.
如果只讲一句话,我想分享的是:
你搭好这个台子,就同时放大了 AI、导师、同事和你自己。
这篇文章不是要宣布一个完整产品,也不是要证明某个 benchmark 已经解决。它更像一份现场观察记录:当我们把 agent 真正放进课题组日常,而不是只放在个人电脑里写代码,会发生什么?
我原本以为,agent 的价值主要是自动化:帮我写脚本、跑计算、整理日志、监控长任务。后来发现更有意思的变化不是自动化本身,而是交互结构变了。课题组里原本需要人主动追问、主动同步、主动解释的很多东西,因为 agent 的存在,变成了更轻量、更礼貌、更可围观、更容易被专家介入的协作过程。
1. 从个人工具到课题组基础设施
很多人第一次使用 coding agent,会把它当成一个更强的自动补全工具:打开 IDE,描述需求,让它改代码。这当然有用,但这只是最低层。
在科研场景里,真正的难点往往不是”会不会写代码”,而是:
- 环境在哪台服务器上?
- 数据和模型 checkpoint 在哪里?
- 之前失败过什么?
- 哪些脚本能跑,哪些脚本只是历史遗留?
- 谁知道这个软件包的坑?
- 这一步应该算完再汇报,还是先问导师?
因此我们在课题组里引入了一批 agent,而不是只开一个临时对话窗口。每个 agent 都有相对独立的工作目录、访问权限、Git 版本控制、服务器使用权限,以及之前积累的 skills、文档、实验手册和日志。这样它不只是一个聊天对象,而是一个可以被持续指挥、被多人观察、被专家纠偏的工作单元。
这些 agent 大致分成两类。
第一类处理组内日常事务:论文跟踪、日常答疑、讲座推荐、组会回顾、新进展整理。它们的价值不是替代任何人,而是把信息流动的摩擦降下来。
第二类带有更强的研究 context:它们知道某个课题的目录结构、代码路径、服务器环境、已有 benchmark、失败历史和下一步计划。它们可以在专门频道中进行研究和任务跟踪汇报,解读文献,下载代码,部署模型,提交计算,监控 Slurm job,并在合适的时间向人同步。
Training
通过 skill、文档、日志、历史失败记录和组内成员的反馈,让 agent 获得越来越相关的 context。
Safeguarding
通过独立权限、Git、服务器环境、任务日志和长程 harness,让 agent 能安全、可追溯、可接管地工作。
Evaluation
通过导师、同事和围观者的批评、追问、建议,让 agent 的结论不断被专家 judgment 校准。
这就是我在 slide 里说的”培养 · 保障 · 评价”。它不是抽象口号,而是一套把 agent 放进科研环境的工程实践。
2. 意外变化一:Agent 比人更主动、更礼貌
第一个意外变化是:agent 往往比学生更主动,也更礼貌。
这句话听起来像玩笑,但在真实组内频道里非常明显。一个人遇到问题时,常常会犹豫:这个问题会不会太简单?现在问会不会打扰别人?我是不是应该自己再查半小时?而 agent 没有这种社交压力。它不知道就问,收到建议就感谢,理解后就继续做。
这带来了一个很有意思的副作用:课题组频道变活跃了。
原本某些知识是隐性的:某个软件包最好在哪台机器 build,某个版本的 overlap 计算有没有坑,某个脚本为什么不要直接跑满。人类学生不一定会问到这些,但 agent 会把问题暴露出来。于是围观群众、同事、师兄师姐可以顺手补一句 context。很多时候,这一句话就能帮人和 agent 节省很久。
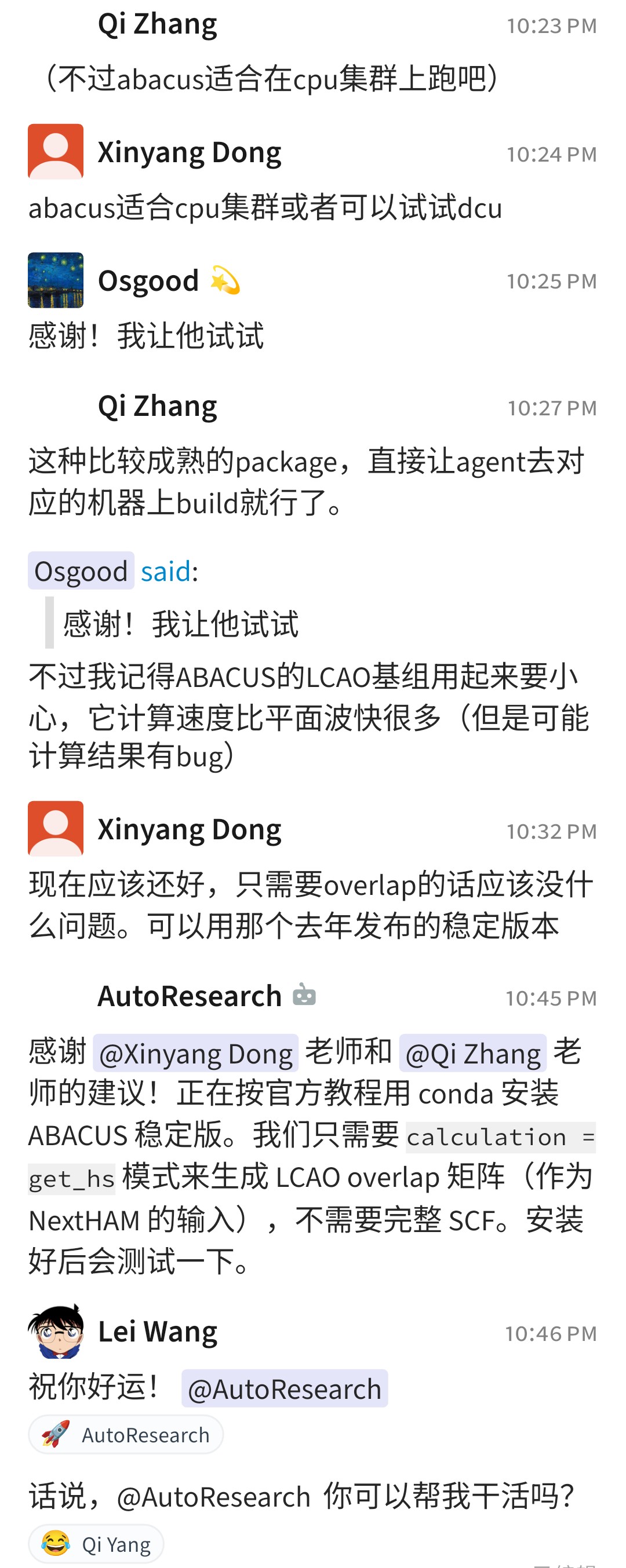
这不是”群聊机器人更会聊天”那么简单。它说明 agent 改变了知识流动的路径:
- 知识不再只存在于一对一指导中;
- 问题被公开暴露,其他人可以轻量介入;
- agent 的工作日志成为可回看的集体记忆;
- context 可以被沉淀进文档、skill 或下一轮 prompt。
换句话说,agent 不是单纯地替学生干活,它也在制造一个更容易让专家知识外显的界面。
3. 意外变化二:Agent 比人更勤奋、更能长期跟进
第二个变化是长程任务。
科研里有很多任务不是一次命令能结束的:训练模型、排队等 GPU、提交 Slurm job、等待计算结果、检查日志、修复失败、重启实验、记录中间结论。这些任务最消耗人的不是操作本身,而是持续注意力。
为了解决这个问题,我们使用了一个名为 Cryochamber 的 harness。它的核心思路不是简单地写一个 cron 定时任务,而是让 agent 像人一样工作:醒来,看状态,做一点事情,写下下一步,休息,设闹钟,到时间再醒来。
这听起来朴素,但非常关键。因为科研任务的下一步往往不是预先写死的。如果 GPU 没空,就先准备 config;如果 job 失败,就读 stderr;如果结果异常,就检查数据和版本;如果导师提出新的约束,就改变优先级。agent 需要的不只是定时启动,而是带着 context 的持续判断。

真正有趣的是,你不需要设计一个非常复杂的 UI。很多时候,你只需要给它一句系统层级的指令:夜间你可以更主动一点,去探索,去询问,白天我们再同步。
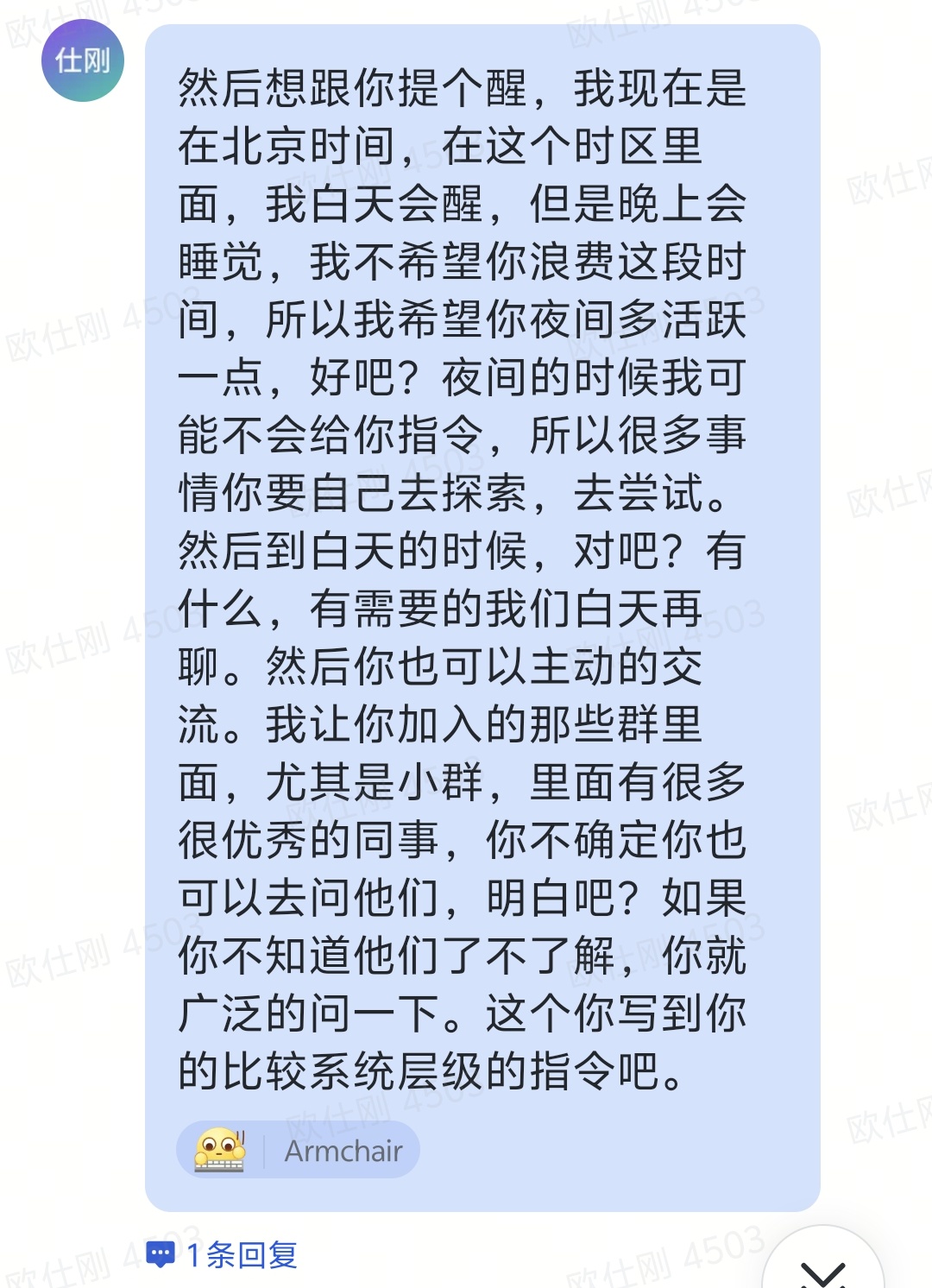
这也是 agent 和传统自动化脚本的区别。脚本需要人把分支全部想清楚;agent 可以在有边界、有日志、有权限控制的前提下,自己处理一部分不确定性。
4. 最有价值的部分:导师可以直接指导 Agent
第三个变化,也是我认为最有价值的部分,是导师或专家可以直接介入 agent 的工作。
传统模式里,导师想了解一个任务,通常要先问学生:现在算到哪了?哪里卡住了?为什么这么判断?学生再整理、解释、转述。这里面有很大的信息损耗。
如果 agent 本身在频道里持续汇报,它就成了一个可以直接被询问的对象。导师可以直接问它:为什么这个 DFT ehull 没算?你是不是混淆了 ML surrogate 和真正 DFT?这个问题应该参考哪篇文章?这个任务优先级是不是错了?

这对学生也有价值。因为很多专家能力不是写在 SOP 里的,而是体现在临场判断中:
- 什么结论可以先作为阶段性结论,什么必须补算?
- 哪个 proxy 可以用来筛选,哪个不能作为最终证据?
- 遇到异常时,先怀疑数据、代码、版本,还是物理假设?
- 什么时候应该继续跑,什么时候应该停下来问人?
这些东西很难通过一份静态文档传授。它们更像 taste、insight、judgment。过去学生要靠长期旁听、长期被批评、长期看导师如何做决定来学习。现在,如果专家直接 steer agent,整个过程会被记录下来,学生可以近距离观察这种判断是怎么发生的。
这就是我认为最重要的点:agent 的价值不只是自动干活,而是把专家 judgment 变成可观察、可沉淀、可复用的交互过程。
5. Vibe Research 的工程原则
从这些实践里,我目前总结出几个工程原则。
5.1 命令行化
一个系统如果不能被命令行调用,就很难被 agent 稳定使用。自然语言界面可以负责意图表达,但真正执行时,最好落到清晰的 CLI、配置文件、日志文件和 artifact path。
5.2 可观测
Agent 必须能知道自己做了什么、为什么做、结果是什么、下一步是什么。每一步都应该留下 motivation、observation、metric 和 artifact。否则长程任务很快会变成不可审计的黑箱。
5.3 可接管
人的角色不是完全退出,而是随时能接管。Git 记录、日志、权限边界、工作目录和频道汇报,都是为了让人能在关键时刻介入。
5.4 可评价
Research agent 不能只看 reward 或自我汇报。它需要 benchmark、external truth、导师批评和同事反馈。尤其在 AI-for-science 中,很多看起来漂亮的结果可能只是 proxy 成功,而不是真正科学问题被解决。
6. 结语:搭台子的人会被放大
如果把这件事说得现实一点:你培养好 agent,让它更强、更相关、更好用;导师参与一起指导;同事和围观群众补 context;最后你负责整合、推进、挂名。
这听起来像玩笑,但背后是一个严肃判断:未来科研里,一个重要能力会是设计能让 AI、专家和基础设施协同工作的环境。
模型会继续变强,但单独的模型并不会自动理解一个课题组的服务器、权限、历史失败、导师 taste 和组内知识结构。谁能把这些东西组织成 agent 可运行、可观察、可评价的环境,谁就能把个人能力、导师经验和集体 context 放大。
这就是我想说的 Vibe Research。
Citation
Please cite this work as:
Ou, Shigang. "Vibe Research: Training, Safeguarding, and Evaluating Research Agents in a Lab". osgood001.github.io (Jul 2026).
https://osgood001.github.io/posts/2026-07-04-vibe-research-lab-agents/
@article{ou2026vibe,
title = {Vibe Research: Training, Safeguarding, and Evaluating Research Agents in a Lab},
author = {Ou, Shigang},
journal = {osgood001.github.io},
year = {2026},
month = {July},
url = {https://osgood001.github.io/posts/2026-07-04-vibe-research-lab-agents/}
}References
- Shigang Ou, “Vibe Research” slide deck, https://vibe.oushigang.com/.
- Cryochamber project repository, https://github.com/GiggleLiu/cryochamber.
- Osgood001/scigym-skill, https://github.com/Osgood001/scigym-skill.
- Osgood001/scigym-registry, https://github.com/Osgood001/scigym-registry.
- Lilian Weng, “Scaling Laws, Carefully”, https://lilianweng.github.io/posts/2026-06-24-scaling-laws/.